Introduction (What are containers)
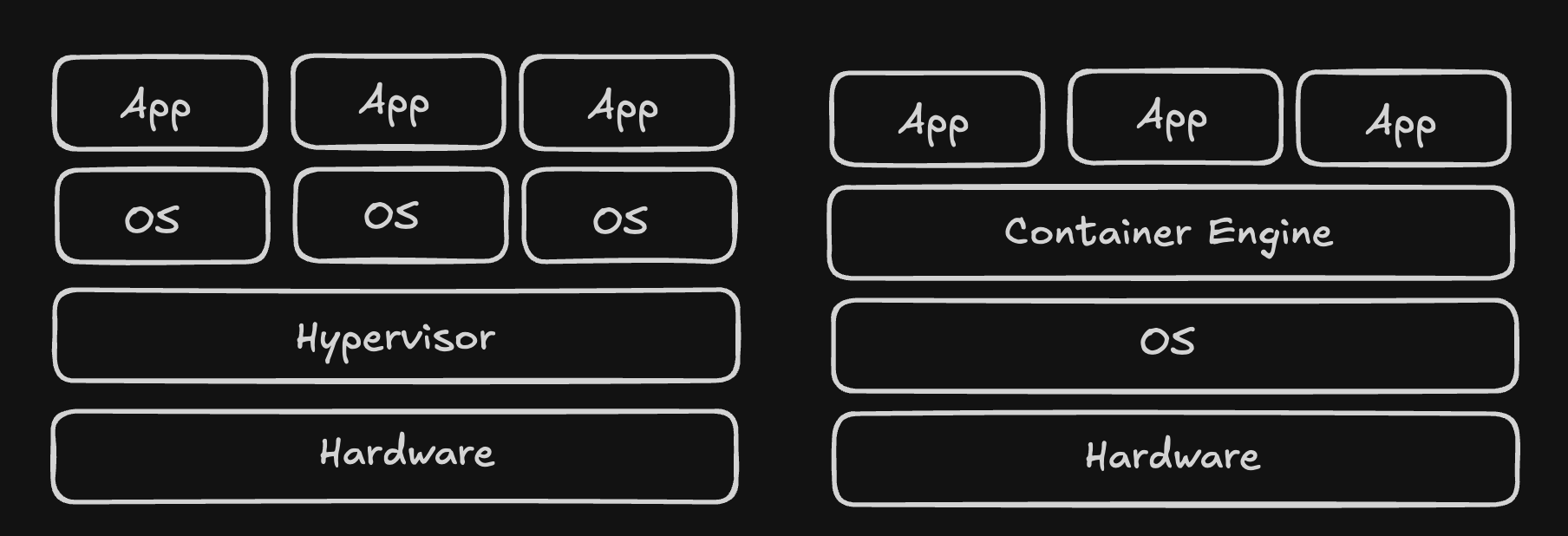
A Container is a defined unit of software, the easiest and most common way to explain containers is through comparison to a Virtual Machine setup. With Virtual Machines, a full computer is simulated with the only shared resource being the bare metal hardware that these VMs run on, containers on the other hand run on a hosts kernel (Operating System) meaning they are much much faster to spin up and down.
Containers in a productive environment are typically managed by some orchestrator such as Kubernetes, if you want a more in-depth view on this technology feel free to read my other post on Kubernetes Overview.
Benefits of Containerisation
Containerisation was invented by Google as a way to more efficiently manage deploy and scale software applications and therefore has many benefits in any software heavy environment such as manufacturing.
Compute Efficiency (Sweat physical asset)
One of the key reasons containerisation was invented was as a way to make better use of compute power, it’s common to see companies with huge VM clusters running at capacity as all RAM, Storage and Compute is allocated to VMs running at 20% utilisation causing companies to buy more and more compute power despite utilising a very small amount of the power available. Typically a VM needs to be specced for it’s peak load and will be constantly allocated those resources, even if it only needs that during peak loading, with containerisation an orchestrator can expand and contract resources dynamically by spinning up more or reducing down containers on demand meaning there is no more “just in case” resource taken.
With this automatic resource provisioning it’s typical to see a move from 10-20% up to 70% asset utilisation, when paired with an IaaS provider this means you truly pay for what you use instead of paying for dormant silicon.
Operating System and Software Lifecycle (Automated Maintenance)
Nobody in the technical world enjoys the constant requirement updating host operating systems and software versions every 3-5 years, and even less business owners enjoy it as a constant expense just to keep their production running with no added benefit.
Now this may seem a surprise as to why I’m calling this out as a benefit as containerisation doesn’t remove OS’s, it actually introduces another semi-OS layer as the host operating system is still required and most containers actually define a lightweight OS base image internal to their container. The reason this however is a benefit is:
- The Host OS is shared between all containers run on the system, this means you could be updating a hand full of host OS’s instead of one for each and every application VM. On top of this, containerisation is very commonly deployed in a cloud or on prem as IaaS meaning these OS’s aren’t even managed by you.
- The OS base image, running within containers, are automatically updated whenever your container is updated requiring no manual intervention beyond using a new Container Image. With this process updating OS’s moves from a complex project to an automatic update when a new version is available or worst case, if you statically define a container version, a 1 line update in in a text file.
Scalability (Improved Reliability)
A real focus for the future of software engineering globally is platform scalability, creating a system that works for minimal and gigantic loads in the same way, FAANG companies are great at doing this such as where Netflix services scale and reduce massively depending on the required streaming demand. One of they key parts of this puzzle is the Microservices architecture backend managed by Kubernetes, although your manufacturing area might not need to scale quite as much as Netflix, as your factory’s data pipeline grows it’s common to start to see performance issues, requiring opex to diagnose and capital to expand and sometimes fully replace, all taking time and money. With a good containerised architecture your systems will scale infinitely with little to no input. If working from a global perspective, this basis of using containers also allows easy scalability between site deployments with standardised/approved containers and deployment architectures that can take seconds to deploy into new sites instead of months with traditional methods.
Rolling Updates (Zero downtime)
Due to the scalability of containers, an orchestration layer like Kubernetes can be used to deploy rolling updates where newer containers are spun up and replace older versions in real time once healthy. This update architecture allows systems to run at full capacity with no detectable downtime externally. This is a great benefit in manufacturing where line time is critical, not only does this remove expensive downtime requirements to complete updates but also removes complications around scheduling and planning.
Platform Agnostic
If you’ve ever had the pleasure of migrating between different hosting platforms, whether that be between different on-prem providers, the move to cloud or back down to on-prem, you know how time consuming and expensive it is just to maintain the same functionality. With a containerised architecture, you don’t define how something runs, you just define what runs. This means, the exact same configuration can be used on any host with no modification, you want to move from azure to AWS, just point AWS to your config and you’re done.
This same platform agnostic architecture means moving from development to production is much less risk, your containers will spin up the exact same environment no matter where they run. With companies adding more and more cyber security and monitoring bloatware to manage systems, the quantity of “It works on my system” errors is increasing daily, with a container the exact same environment is setup no matter what surrounds it massively reducing this migration/integration error.
Continuous Integration and Continuous Deployment
Although containerisation doesn’t intrinsically bring CICD, it infinitely reduces the complexity of implementation. The power to easily and reproducibly spin up and down containers means not only the production environment can be automated but also the testing environment. With the creation of a CICD pipeline, amongst other things you can automate:
- Pulling images from a vendor to always stay up to data
- Functional testing of the application
- Security scanning for code vulnerabilities
- Push to internal image repo
- Deployment to production
- Rollback in event of bad update Hopefully this highlights how powerful the deployment of a robust CICD pipeline is, not only massively reducing the manual effort but also massive improvements to both the speed of updates and cyber security.
Concerns of containerisation
Although containers are an incredibly powerful tool that solves many of the pain points we face today in the world of software in manufacturing, it isn’t a silver bullet that solves all issues with no other considerations.
Security concerns
Due to the software architecture of VMs where each application and system have their own isolated operating system, they are great at segmenting and reducing impact of a cyber attack or breach. With containers however, the applications you run are run by a shared operating system, as such a cyber attack to a single container can give a cyber attacker an escalation route through to all other containers and host system.
This is a very well known and understood risk within the containerisation world and although there isn’t one single answer to fix this, there are many mitigations you can implement to massively reduce that risk such as: Security scanning, minimal base images, least privilege execution, system monitoring and nano-segmentation among many more.
Skills gap
Although this isn’t a technical limitation, I’d be remiss if I didn’t mention the change in skills required to support this architecture. It is probably the largest hurdle to start using containers in any function, although being widely adopted through any technology company, traditional automation teams are generally un-familiar with the concept, process and tools involved in setting up and maintaining this architecture. If there’s one part of deploying a containerised architecture that’s going to trip you up, it’s not the tools, technology or cost, it’s if people don’t understand it or want it. As with all change, it’s a whole lot easier to stay the same than do something new, and containerisation will be very new to most of the current workforce.
How containerisation can be deployed
For those wanting to see what that looks like in real life, and as an excuse for me to have a play myself, I wanted to pull together a little example; I’ve made a little example using ignition based on one of the architectures proposed by the Ignition team for a larger-scale platform. A little heads up, this is very much an example I’ve collated myself quickly and is not something I’m suggesting be copied and pasted into production.
Ignition SCADA Example
When going through the Ignition documentation, an architecture is proposed for larger systems where separate ignition servers are spun up to deal with tag reads and general backend tasks with then separate frontend servers that handle client requests and visuals without impacting the backend performance, to ensure demand is managed these front end servers are passed through a load balancer to use all of these servers.
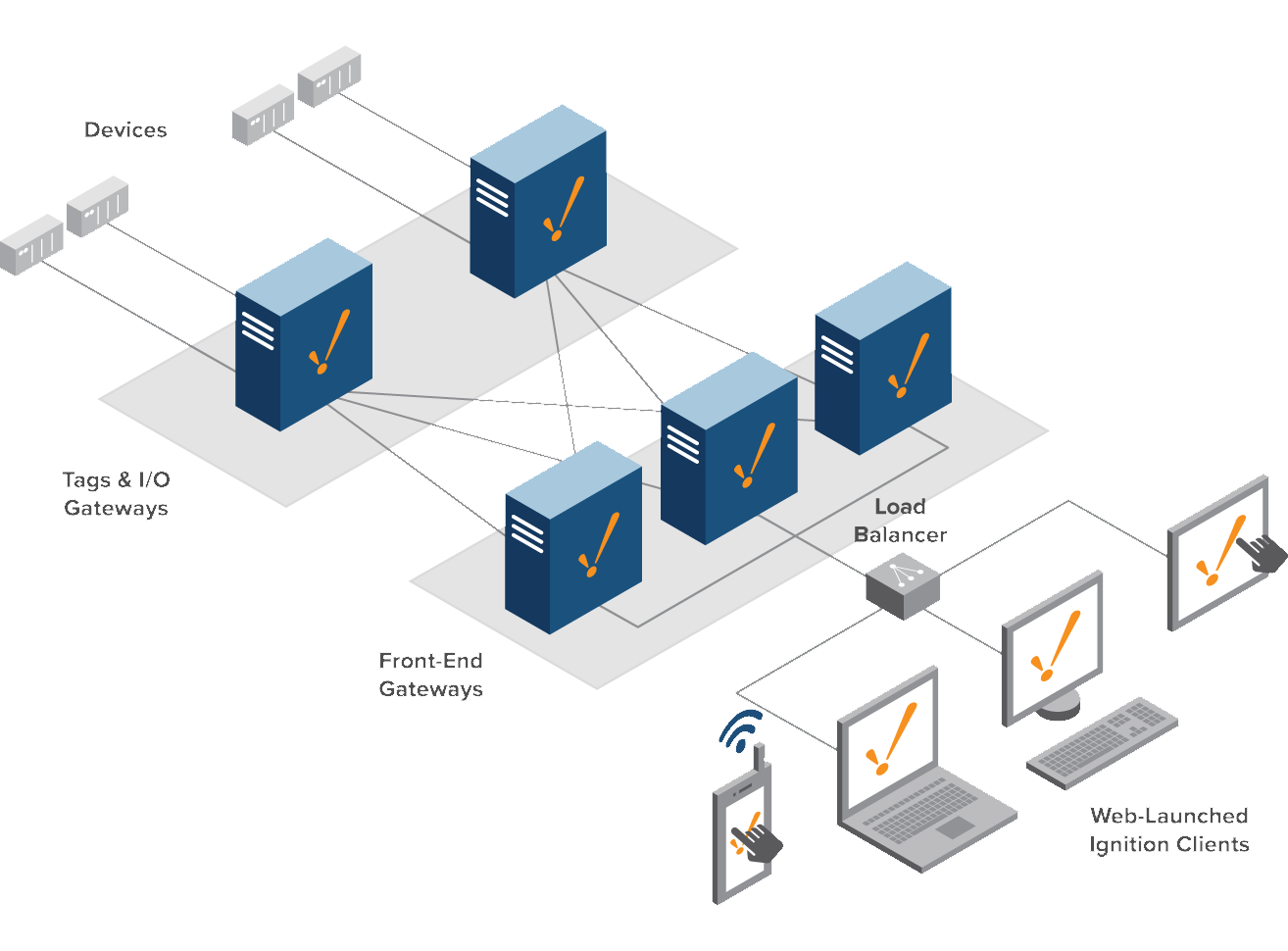 In my mind, this architecture is perfect for a Kubernetes and thankfully Ignition already has a publicly available container image on Docker Hub. I decided to spin up three backend ignitions (I think there’s a better way to do this than I’ve done in my config), with a horizontally scaling set of front end ignitions. As you can see in the below diagram, each backend ignition has its own volume for storing individual configuration and has a separate port to access its webpage, for the frontend a single volume and port means all frontend servers will use the same configuration and be connected to over the same port allowing kubernetes to load balance which application you’re actually talking to without you knowing.
In my mind, this architecture is perfect for a Kubernetes and thankfully Ignition already has a publicly available container image on Docker Hub. I decided to spin up three backend ignitions (I think there’s a better way to do this than I’ve done in my config), with a horizontally scaling set of front end ignitions. As you can see in the below diagram, each backend ignition has its own volume for storing individual configuration and has a separate port to access its webpage, for the frontend a single volume and port means all frontend servers will use the same configuration and be connected to over the same port allowing kubernetes to load balance which application you’re actually talking to without you knowing.
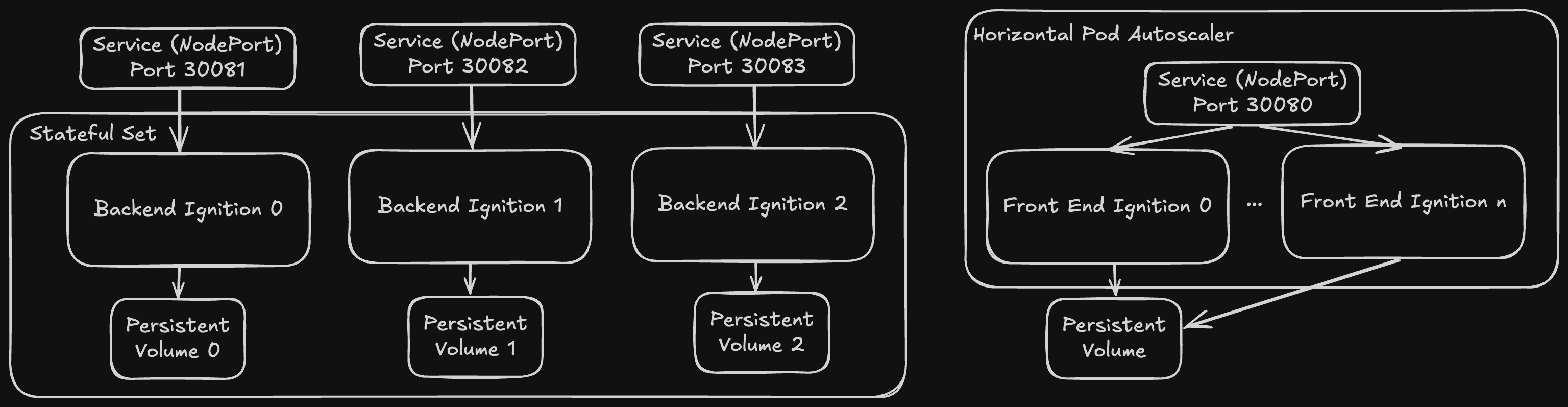
If you’d like to take a look into the configuration, run this yourself or improve it (Let me know if you do), please see below the kubernetes manifest:
# ---------------------------------------
# Frontend Deployment
# ---------------------------------------
apiVersion: apps/v1
kind: Deployment
metadata:
name: ignition-frontend
spec:
selector:
matchLabels:
app: ignition-frontend
template:
metadata:
labels:
app: ignition-frontend
spec:
containers:
- name: ignition
image: inductiveautomation/ignition:latest
ports:
- containerPort: 8088
name: https
volumeMounts:
- name: shared-config
mountPath: /config
volumes:
- name: shared-config
persistentVolumeClaim:
claimName: frontend-config-pvc
# ---------------------------------------
# Frontend Shared PVC
# ---------------------------------------
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: frontend-config-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
# ---------------------------------------
# Frontend Scaling
# ---------------------------------------
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: ignition-frontend-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ignition-frontend
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
# ---------------------------------------
# Frontend Service
# ---------------------------------------
---
apiVersion: v1
kind: Service
metadata:
name: ignition-frontend
spec:
type: NodePort
selector:
app: ignition-frontend
ports:
- name: https
port: 8443
targetPort: 8088
nodePort: 30080
# ---------------------------------------
# Backend StatefulSet
# ---------------------------------------
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: ignition-backend
spec:
selector:
matchLabels:
app: ignition-backend
serviceName: "ignition-backend"
replicas: 3
minReadySeconds: 10
template:
metadata:
labels:
app: ignition-backend
spec:
terminationGracePeriodSeconds: 10
containers:
- name: ignition
image: inductiveautomation/ignition:latest
ports:
- containerPort: 8088
name: https
volumeMounts:
- name: www
mountPath: /config
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "hostpath"
resources:
requests:
storage: 1Gi
# ---------------------------------------
# Backend NodePort Services (1 per pod)
# ---------------------------------------
---
apiVersion: v1
kind: Service
metadata:
name: ignition-backend-0
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: ignition-backend-0
ports:
- name: https
port: 8443
targetPort: 8088
nodePort: 30081
---
apiVersion: v1
kind: Service
metadata:
name: ignition-backend-1
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: ignition-backend-1
ports:
- name: https
port: 8443
targetPort: 8088
nodePort: 30082
---
apiVersion: v1
kind: Service
metadata:
name: ignition-backend-2
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: ignition-backend-2
ports:
- name: https
port: 8443
targetPort: 8088
nodePort: 30083